
How I Build with AI: February 2026
Every line exists because something breaks without it

TL;DR
I used to run a kanban-style directory structure with state machines for task tracking. Models and tooling got good enough that it collapsed into a section in CLAUDE.md
Start in Plan Mode: same philosophy as working with an engineer—align on the approach before anyone touches code
Every commit has validation criteria: a concrete pass/fail the agent uses to self-check, and which reviewers use to verify if the implementation does what was expected. Distrust and validate.
Preference negotiation before the plan is finalized: review frequency, commit strategy, review cycles—same process, different dial based on whether you’re building a POC or production code
Two aggressive reviewers per commit—a senior engineer for architecture and code quality, a test reviewer for test quality. Focused agents produce better outcomes. Quality is what gives you speed.
“No shortcuts. No laziness. Quality is non-negotiable.” This needs to be in the config—Claude Opus 4.5/4.6 biases toward speed as context fills up; making it explicit raises the floor
From kanban directories to a config file
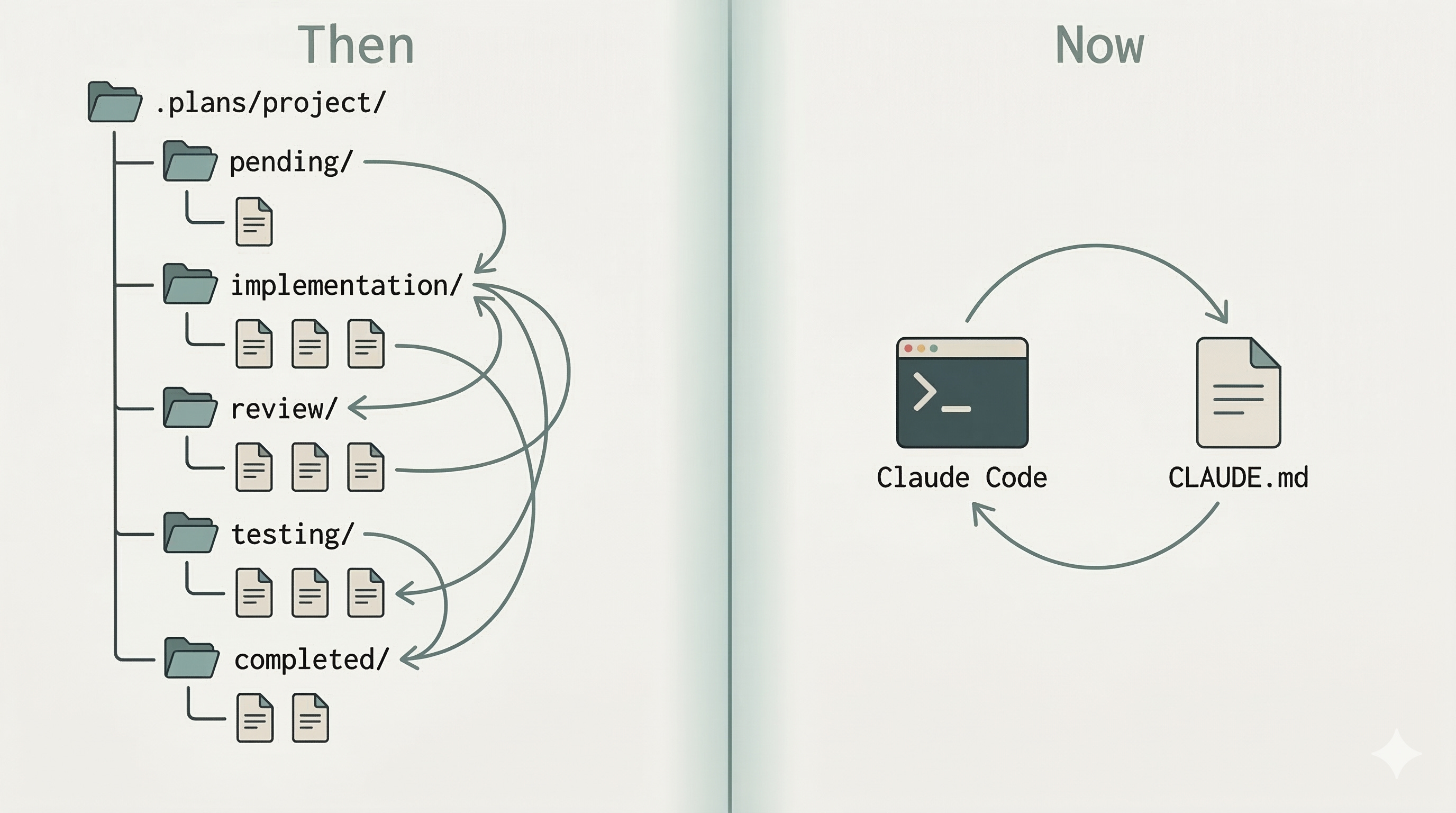
That’s what my workflow looked like last year. A .plans/ directory, subdirectories for each project, task files moving between pending/ → implementation/ → review/ → testing/ → completed/. Commands to invoke at each stage. State to track.
This is what it looks like now.
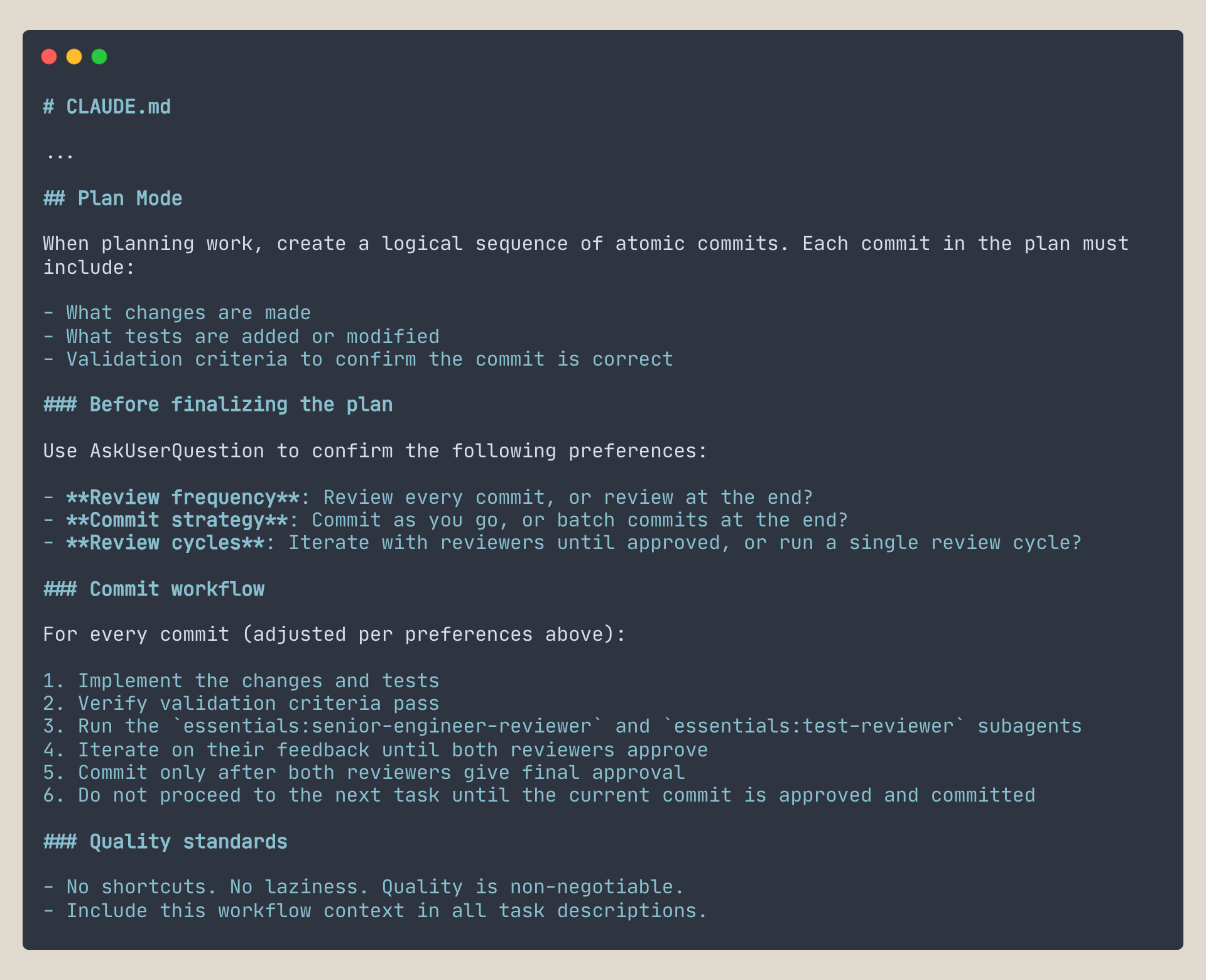
The whole thing collapsed into a Plan Mode section in CLAUDE.md. Same outcomes—autonomous execution, review cycles, quality gates—but the platform absorbed the scaffolding.
Models got better at following structured instructions without needing machinery around them. Claude Code’s native Tasks feature replaced the kanban directories. Plans now live in the filesystem as markdown files; no shuffling files between folders.
What’s left is the config.
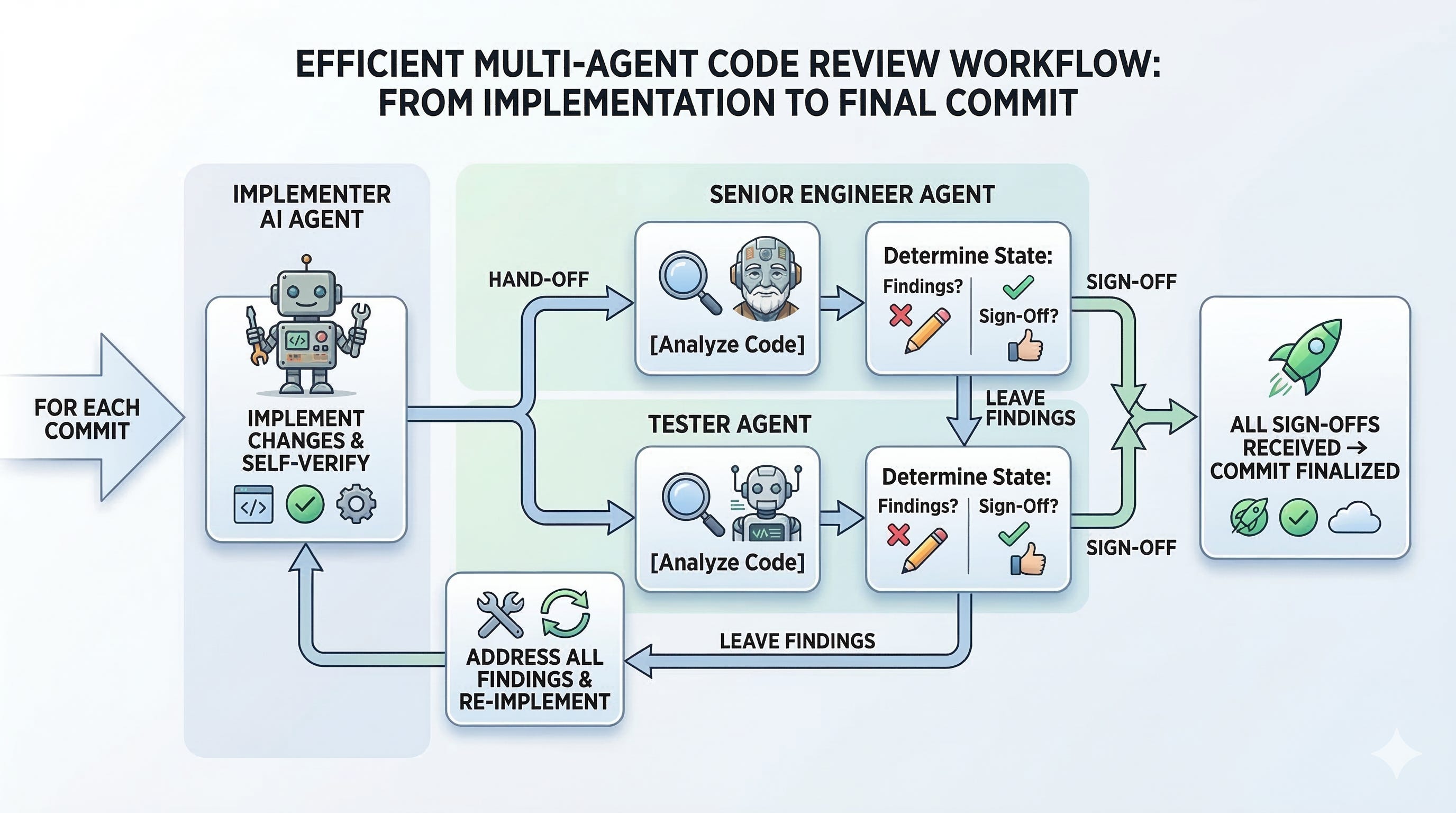
One agent implements. Two review. For each commit: implement, verify, and hand off to both reviewers in parallel. They leave findings. The implementer addresses them. The loop repeats until both reviewers sign off—then you commit. A single commit can go through 3-4 review cycles before that happens.
Rule zero: always start in Plan Mode
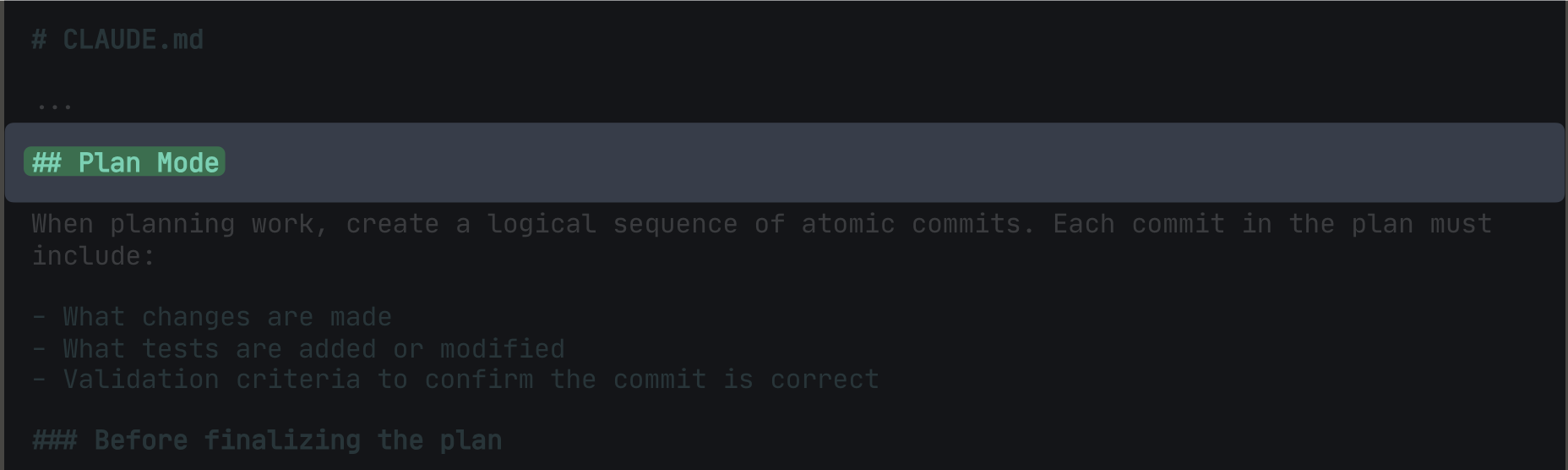
I work with Claude Code the same way I’d work with an engineer. You don’t hand someone a task and walk away—you talk it through first. What are we building, how are we approaching it, and what does done look like? Then they go.
Plan Mode is that conversation—alignment before code. You see what the agent will do before it does anything—and if something’s off, you catch it now instead of three commits later.
Without it, the agent optimizes locally—figuring things out on the go, making decisions commit by commit without seeing the full picture. I’ve had tasks where skipping Plan Mode caused the agent to go in a completely different direction from what I intended. Or turned a small change into a full refactor because it decided it needed to restructure first. Undoing that is expensive. Planning upfront means the agent sees the problem holistically, not just the next step.
Atomic commits—the unit of work
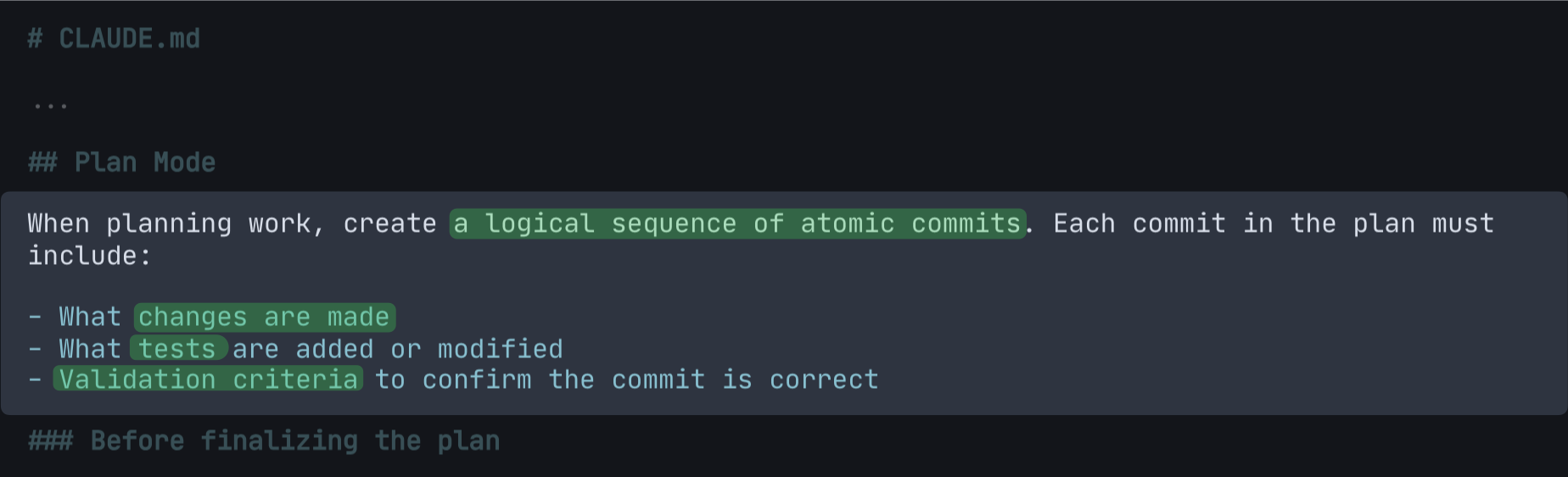
Every commit in the plan includes three things: the changes made, the tests added or modified, and the validation criteria.
The first two are obvious. The third is the important one.
My default when working with agents is to distrust and validate. Agents take shortcuts. They skip steps, drift from the requirements, and—if left unchecked—produce something that looks right without being right. Validation criteria is the fix: a specific, objective check that tells the agent what “done” actually means. Not interpretation—a concrete pass/fail the agent can verify before handing off, and that reviewers can check against.
Without it, the agent has no way to know if it’s actually done the right thing. It becomes a human-in-the-loop process—you review every commit, course correct, and verify manually. That doesn’t scale past small tasks.
Preference negotiation
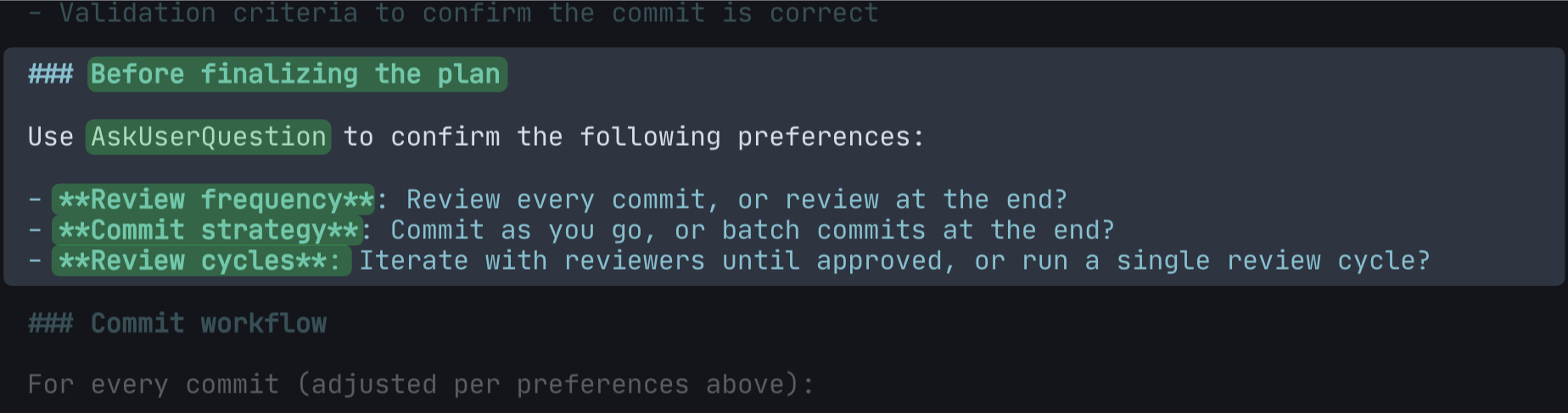
Before the plan is finalized, the agent asks three questions: How often do you want to review—after every commit or at the end? Commit as you go, or batch at the end? One review cycle per commit, or iterate until approved?
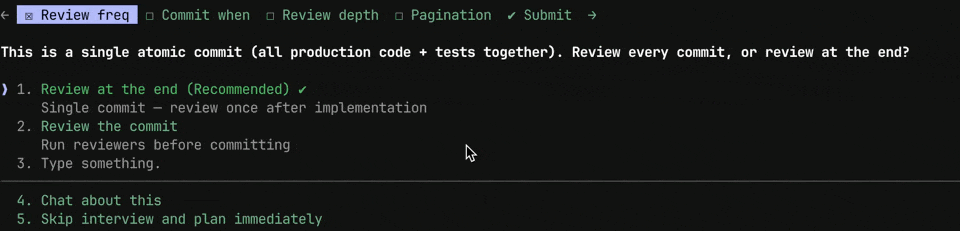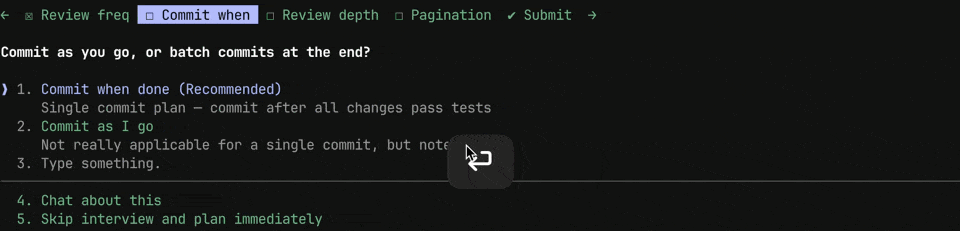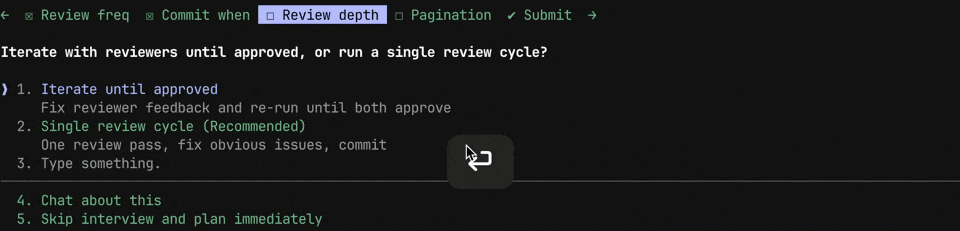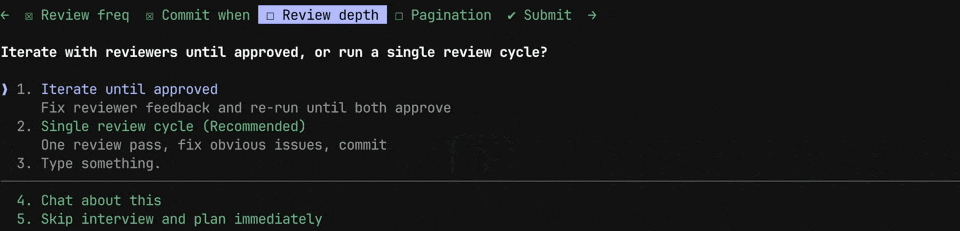
Not all work is equal. A POC you want to move through quickly is a different scenario from production code you’ll maintain for the next two years. Same process, different dial. Asking upfront means the workflow matches the task—fast and low-ceremony when complexity is low, thorough and deliberate when quality needs to hold up over time.
The commit loop
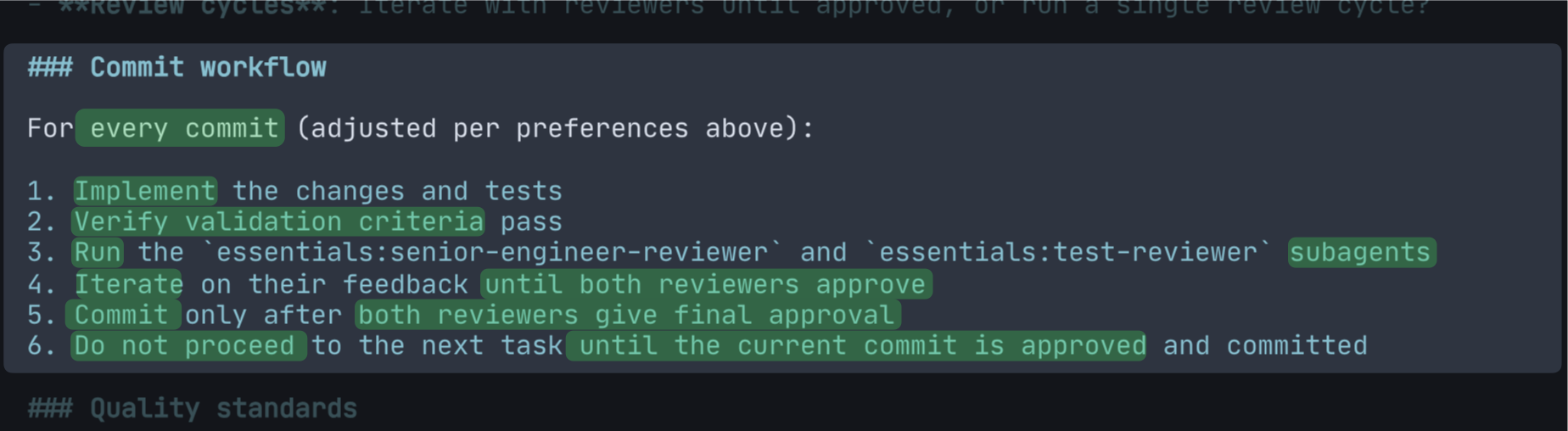
This is the engine. Everything else exists to make this work.
Implement. Verify against the criteria. Hand it off to both reviewers in parallel. Address their findings. Loop until both sign off. Commit. Move to the next.
The order matters. Verification happens before review—the implementer doesn’t hand off work that hasn’t been checked against its own definition of done. And you don’t proceed to the next commit until the current one is approved—no half-finished work accumulating in the background.
The workflow lives in the plan file—once planning is done, the process steps are always in context. The agent doesn’t forget what it’s supposed to do. (It can still cut corners on effort as context fills up—that’s a different problem, addressed in the quality standards section.)
Each commit is also a verified green state. When the next task starts, everything that came before is done, reviewed, and working. If something goes wrong mid-session, you’re never far from solid ground—fall back to the last commit and start again.
The review agents


Two reviewers, not one. Not more.
More reviewers means more tokens per review cycle—and past a certain point, you’re paying for noise, not signal. There’s also a practical ceiling: in my experience, the more instructions you give an agent, the worse it performs—and that effect gets worse with less capable models. Focused agents produce better outcomes.
The two things I will not compromise on: decisions that make the system hard to extend, and tests that give a false sense of security—one reviewer for each.
Senior engineer reviewer—for architecture, design decisions, and code structure. Not just whether it works, but whether it’s built in a way that won’t become a burden.
Test reviewer—test quality exclusively. Missing edge cases, boundary conditions, and security checks. Tests that inflate coverage without increasing confidence are worse than no tests. This gets its own reviewer because test quality is important enough not to share attention with anything else.
Both are deliberately hostile. I’d rather have more comments to work through than fewer polished ones. A polite reviewer gives false confidence. An aggressive one gives you more to filter—but what survives is actually solid.
Quality is what gives you speed—not short-term speed, but the kind that compounds and helps you move faster.
Without them, you’re trusting the implementer to catch its own mistakes. It won’t.
Quality standards—why you have to say it

The CLAUDE.md has a line that reads: “No shortcuts. No laziness. Quality is non-negotiable.”
It needs to be there. I added it after noticing a specific pattern: Claude Opus 4.5 and 4.6 have a bias toward moving fast, and that bias gets stronger as the context fills up. The agent starts skipping ahead rather than slowing down to fix things properly. That line directly addresses it.
Before I added it, the pattern was clear: the agent would ignore review feedback, deem findings unimportant, and move on, or skip the review step entirely.
Since adding it, the agent’s behavior has changed noticeably. Critical and major issues get addressed. And something I didn’t expect: even minor feedback that doesn’t require much work—the agent handles it and moves on. No pushback, no deferral.
There are still occasional lapses. But the floor is higher.
With AI, compromising on quality is a choice, not a constraint. The cost of writing quality code is near zero. If quality slips, the instructions allow it. So the instructions don’t.
When there’s exploration involved
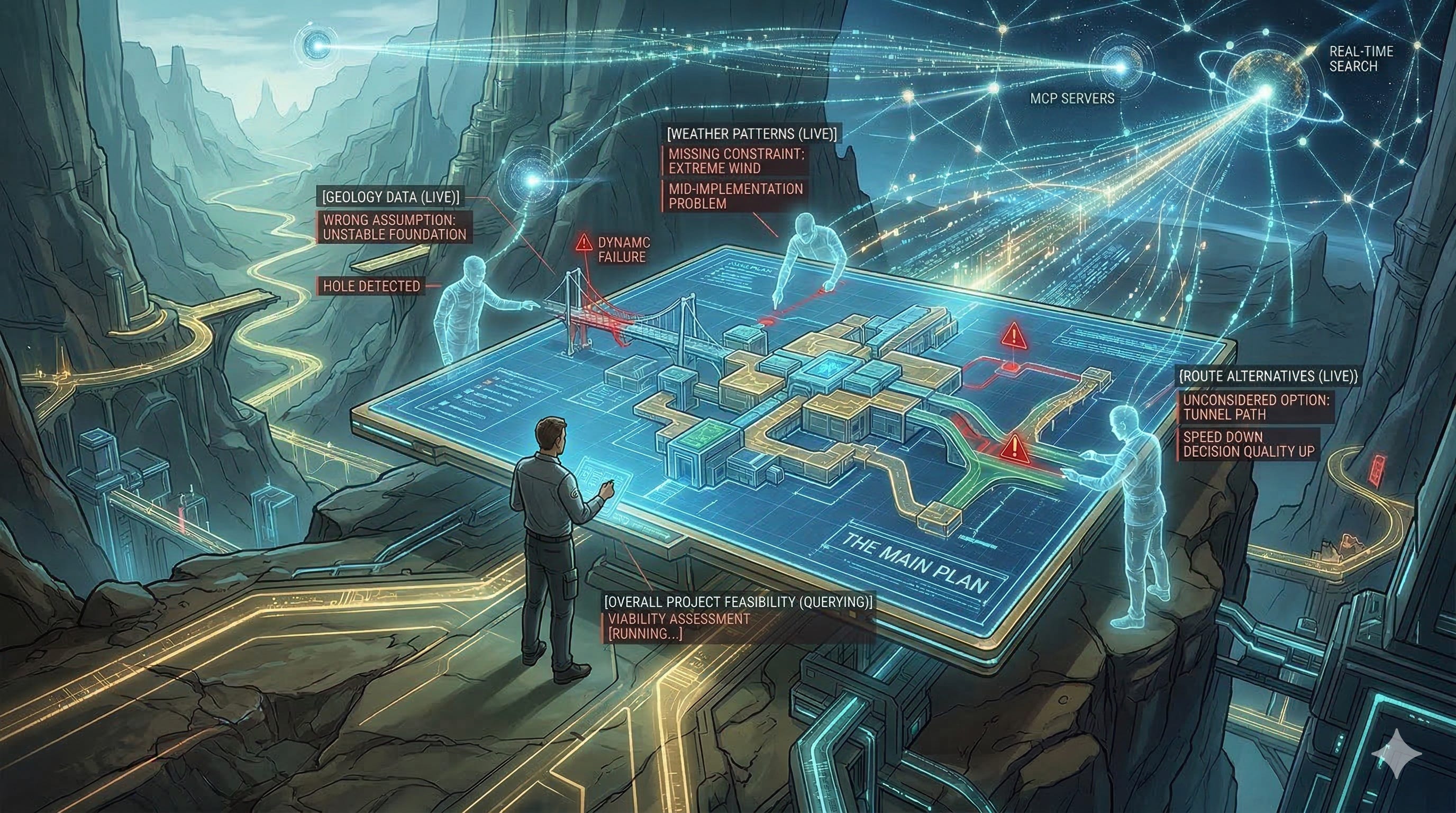
The workflow above assumes you know roughly what you’re building. When you don’t—unfamiliar technology, unclear approach, high unknowns—planning needs an extra step.
I work with the agent to develop a plan, but before committing to the plan, I spawn 2-3 “adversarial” sub-agents to critique it. Their job is to find holes: wrong assumptions, missing constraints, options I haven’t considered. It’s a pre-mortem before any code exists. Speed goes down. Decision quality goes up. Problems that would have surfaced mid-implementation get caught before any code is written.
One thing that makes this work is having MCP servers or real-time search in your coding setup. Plans built on current information just fail less often in execution.
Limitations
The workflow isn’t perfectly calibrated. Review agents spawn for every commit—including trivial ones where the overhead isn’t worth it. A documentation update goes through the same loop as a complex feature, with the same reviewers. That’s not ideal—different tasks need different reviewers. A doc change doesn’t need a senior engineer; it needs something focused on documentation quality.
The cleaner solution would be to move this out of CLAUDE.md entirely—into a separate skill that dynamically selects reviewers based on the nature and complexity of the change. I haven’t built that yet, so I've kept it simple for now.
The review loop consistently catches real problems. The overhead calibration is where it’s still rough.
Where this goes
Simpler systems are easier to work with, manage, and change. Every time models improved or tooling improved, I saw it as an opportunity to simplify—not to add more. The end outcome has stayed roughly the same. The system is a fraction of what it used to be.
What feels like necessary scaffolding right now probably won’t be soon.
Here are the links to the artifacts I mentioned:
If you want to follow along beyond the blog, find me on Twitter/X at @dhruvbaldawa. I’d love to hear your thoughts—what topics around AI and developer productivity are you most curious about?
Hi this was a nice read. Thanks for links to your files. While I was exploring the repo I found the commands section. Like the `commit.md` are they also required for the above described approach to work ?
I am also finding adversarial operations are productive. That is the only thing that research is telling us is proven to help. E.g. ask Claude to remove redundant tests after writing tests. Try asking Claude about the utility of the instructions you are giving it. Here is my CLAUDE.md. I am writing a very specific kind of system code so it gets very particular about optimization: https://github.com/whatchamacallem/libhatchet/blob/main/CLAUDE.md